Définition
Conception et maintenance de pipelines ETL (Extract, Transform, Load) en environnement professionnel, visant à collecter, nettoyer, transformer et fiabiliser des données issues de systèmes hétérogènes.
Ces projets s’inscrivaient dans une logique d’industrialisation des flux de données, avec des exigences fortes de stabilité, traçabilité et performance.
Mise en pratique
- Analyse des sources de données (bases relationnelles, exports métiers, fichiers externes).
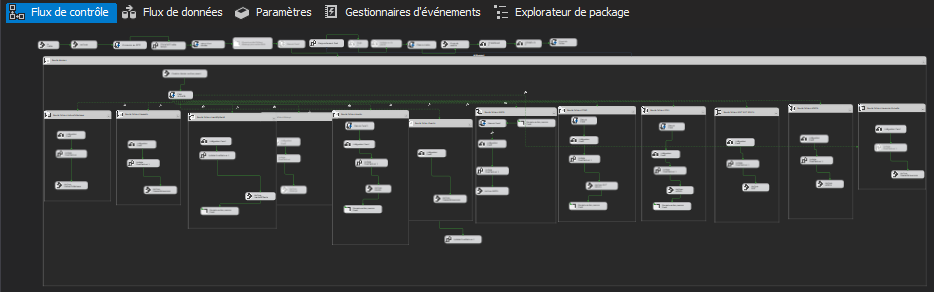
- Conception de flux SSIS pour l’orchestration des extractions et chargements.
- Implémentation de transformations métier (normalisation, déduplication, enrichissement).
- Nettoyage et validation des données via scripts Python ou Powershell (contrôles qualité, cohérence).
- Mise en place de mécanismes de journalisation et gestion d’erreurs.
- Optimisation des performances sur des volumes importants.
- Documentation technique et structuration des flux pour assurer leur maintenabilité.
Acteurs & interactions
Équipes métier (comptabilité, contrôle de gestion) pour la définition des règles et la validation des flux ; équipe IT pour l’infrastructure et le déploiement. Coordination pour formaliser les règles de transformation, les contrôles qualité et les seuils d’alerte. Documentation et échanges réguliers pour anticiper les évolutions des sources et les impacts.
Contraintes & enjeux
- Qualité des données : garantir la cohérence et la fiabilité des informations.
- Performance : traitement de volumes significatifs sans dégradation des temps d’exécution.
- Traçabilité : journalisation claire des traitements et des erreurs.
- Maintenabilité : éviter les flux monolithiques difficiles à modifier.
- Sécurité : manipulation de données sensibles dans un cadre réglementé.
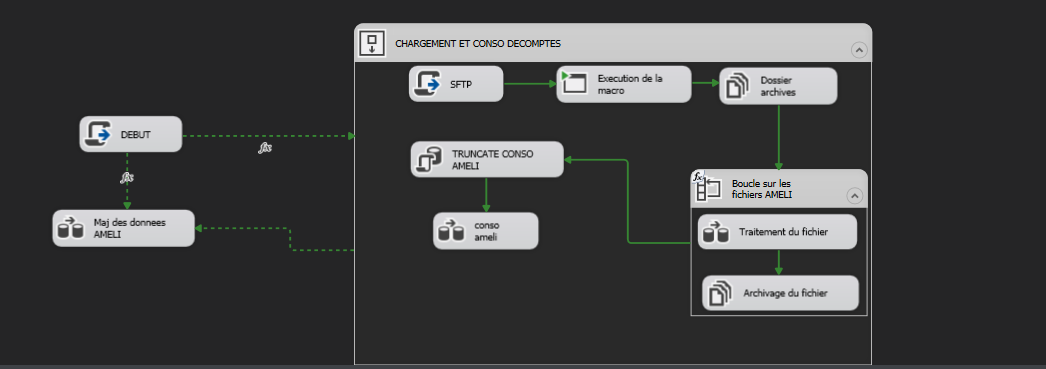
Vue technique : déroulement d’un process ETL de base
Un process ETL (Extract, Transform, Load) vise à alimenter une cible de données à partir de sources hétérogènes, en garantissant cohérence, qualité et traçabilité. Voici les phases d’un déroulement de base.
Extract (extraction)
Les données sont lues depuis les sources : bases relationnelles (requêtes SQL, connexions ODBC/OLE DB), fichiers plats (CSV, Excel, positions fixes), APIs ou exports métiers. Les extractions peuvent être complètes (full) ou incrémentales (delta) selon la volumétrie et la fréquence. Les connexions, requêtes et chemins sont paramétrés pour limiter la duplication de logique et faciliter la maintenance.
Transform (transformation)
En ETL classique, les données sont transformées avant chargement : normalisation (formats de dates, unités, codifications), déduplication, filtrage des doublons ou des enregistrements invalides, enrichissement (jointures, calculs, mise en conformité métier). Avec chargement préalable en zone de staging, les données sont d’abord chargées dans une zone de staging, puis les transformations sont appliquées (souvent en SQL ou dans un moteur de données) pour réduire la charge sur les sources.
Load (chargement)
Les données validées sont chargées dans la cible : tables de base de données, data warehouse, fichiers de sortie. Le chargement peut être en insertion (insert), mise à jour (upsert) ou remplacement (truncate + load) selon les règles métier. Les contraintes d’intégrité et les index sont gérés pour préserver les performances et la cohérence.
Contrôles et journalisation
Des contrôles qualité sont exécutés (nombre de lignes lues/écrites, contrôles de cohérence, détection d’anomalies). Toute étape est journalisée (début, fin, volume, erreurs) pour la traçabilité et le diagnostic. En cas d’échec, le process peut être conçu pour reprendre à partir du dernier point de contrôle ou alerter sans laisser la cible dans un état incohérent.
En résumé : un process ETL de base enchaîne extraction des sources → transformation → chargement vers la cible → contrôles et journalisation, avec une attention constante à la qualité des données et à la reproductibilité des exécutions.
Résultats
- Mise en place de pipelines ETL robustes et industrialisés.
- Amélioration de la qualité et de la cohérence des données.
- Réduction des traitements manuels et des erreurs associées.
- Stabilisation des flux quotidiens/hebdomadaires critiques.
Ces projets ont renforcé ma compréhension des problématiques de gouvernance et de qualité des données.
Mon autocritique
Niveau 7.5/10.
La dimension technique est solide, notamment sur la robustesse et la structuration des flux.
La principale valeur ajoutée réside dans la capacité à transformer des flux complexes en pipelines stables, lisibles et maintenables.
Évolution
- Formalisation plus systématique des schémas de données en amont.
- Mise en place d’indicateurs de qualité des données automatisés.
- Migration progressive vers des architectures data plus modernes (orchestration avancée, monitoring centralisé).
Regard critique
Avec le recul, l’amélioration principale concernerait la documentation initiale des règles métier et des transformations.
Une approche davantage orientée “data architecture” dès le démarrage (diagrammes de flux, mapping structuré) renforcerait encore la lisibilité globale et la gouvernance.